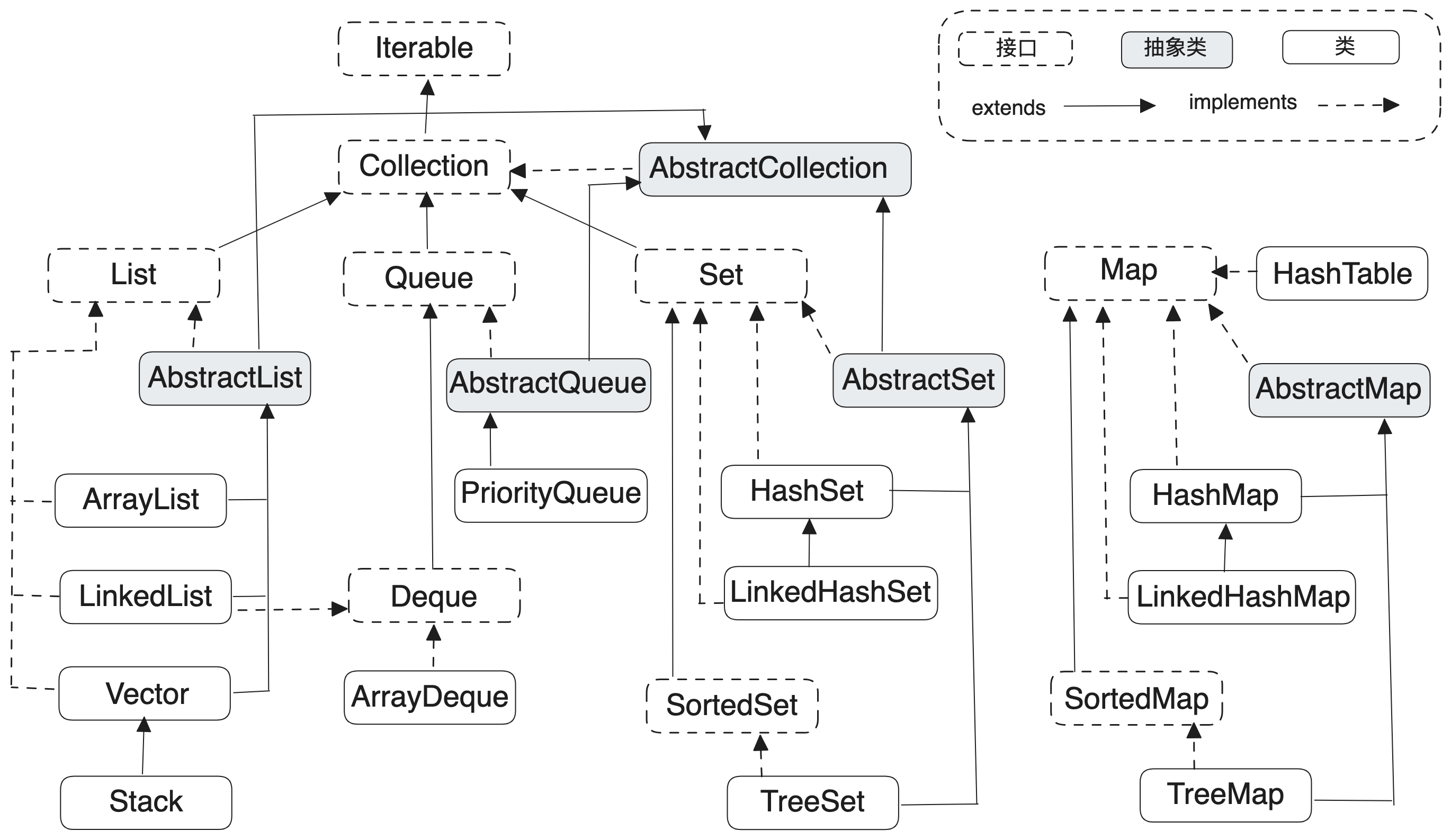
容器总览
关于ArrayList和LinkList的准确描述
ArrayList并不是所有的插入都是很慢的,如果是数据的数量没有超过数组的最大值,并且还是插入到最后,那么这个时候插入也是O(1)的复杂度。只有ArrayList每次都在插入到首位才是O(n)的复杂度,英文对应的数据都要向后进行移动。
同样LinkList也不是所有的插入都是快的,对于双向链表来说,插入头部和尾部都是很快的,但是如果插入到LinkList的中间,那么时间也是O(n)的复杂度,因为这个时候的大部分时间都浪费在遍历上。
LinkList的的插入分为两部分
- 寻找到插入的位置;这个动作可能耗时比较久
- 插入元素;这个动作是耗时很少的
优先队列
java中提供了一个PriorityQueue的优先队列,这个优先队列的底层依赖堆这种数据结构来实现。默认情况下是实现的
小顶堆来实现的。如果要实现
大顶堆那么改变下实现的比较逻辑即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// 默认为小顶堆实现的优先级队列
PriorityQueue<Integer> pq = new PriorityQueue<>();
pq.add(2);
pq.add(3);
pq.add(1);
while (!pq.isEmpty()) {
System.out.println(pq.poll()); //输出1、2、3
}
// 改为大顶堆实现的优先级队列
PriorityQueue<Integer> rpq =
new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
});
rpq.add(2);
rpq.add(3);
rpq.add(1);
while (!rpq.isEmpty()) {
System.out.println(rpq.poll()); //输出3、2、1
}
上面的实现是通过Comparator的方式来进行灵活控制,如果是一个实体类,并且想使用一个固定的比较方式,那么可以让该实体类实现
Comparable接口。ps: 其实看源码都可以解决自己的疑问,源码里面会有个判断Comparator是否进行了初始化,如果Comparator进行了初始化,那么就使用这个,如果没有进行初始化则使用对应的
Comparable接口。
1
2
3
4
// 实现Comparable
public class Student implements Comparable<Student> {
// ....
}
Set集合
Set的集合包括HashSet、LinkedHashSet、TreeSet。这三个Set分别底层依赖的是HashMap,LinkedHashMap,TreeMap.
实际上就是存入的值当做key,空的Object对象作为value。
Collections常用方法
sort排序
有这两种排序方式,一种是调用sort方法的时候传入Compator的实现,一种是对象就实现了Comparable的接口。
1
2
public static <T extends Comparable<? super T>> void sort(List<T> list);
public static <T> void sort(List<T> list, Comparator<? super T> c);
Collections中常用的的排序方法其实还是调用的Arrays中的sort排序方法。(其实List容器中的排序方法也是使用的Arrays的排序方式)
Arrays类的sort()函数是使用哪种算法实现的呢?
| JDK7 | JDK8 | |
|---|---|---|
| 对象数组 | 归并排序 | TimSort |
| 基本类型数组 | 快速排序算法 | DualPivotQuickSort |
源码分析后续再讲解 todo
HashMap
HashMap可以从以下几个方面来进行总结和复习
- 特性
- hash函数
- 键的不可变性
- 装载因子
- 动态扩容
- 链表树化
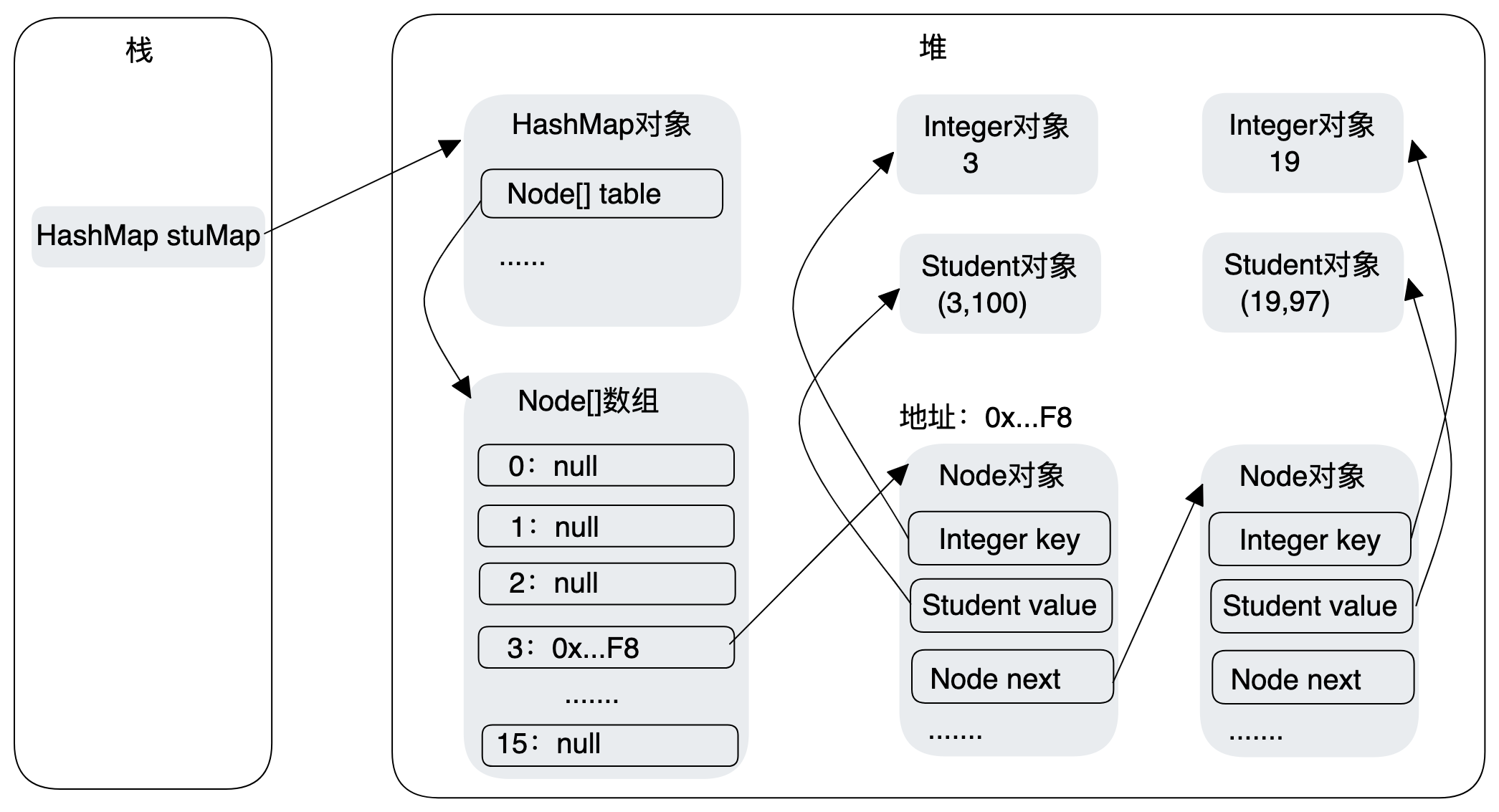
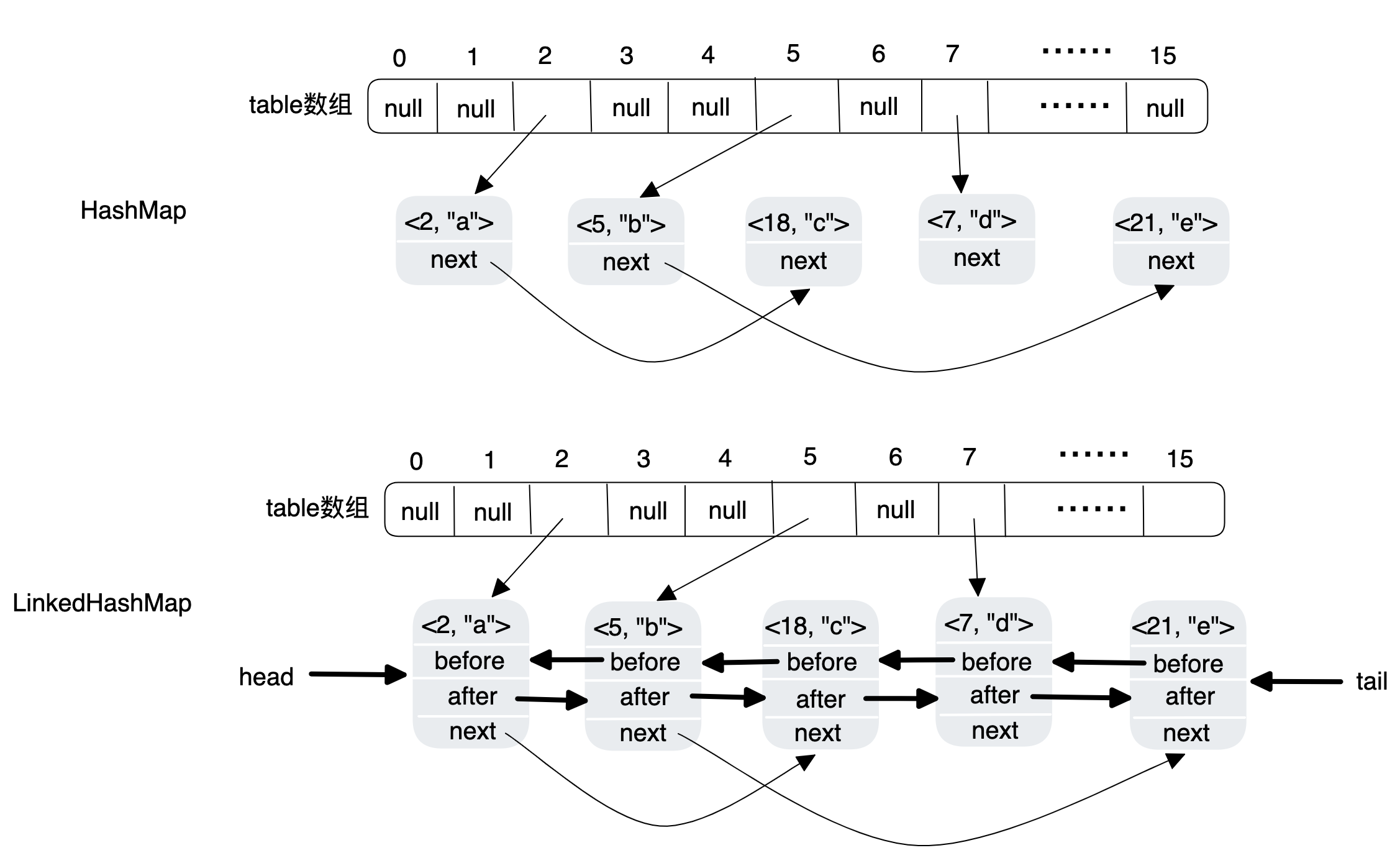
HashMap是以键和值配合存储的数据结构,键可以为null,如果多个键一样的会以最新的值为准,也就是代替。
当发生Hash冲突的时候,还会以链表的形式进行保存。当链表的长度达到8的时候,会由链表转换成红黑树。
HashMap容器的数组长度n的默认初始值为16。
哈希函数
1
2
3
4
5
static final int hash(Object key) {
int h;
// 使用^(异或) 的形式可以让0和1分布的更随机一点
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
使用与的位运算来判断key应该存储到那个数组的下面
1
2
// 因为hash得到的值很大,很可能超过数组的长度,所以要进行取模
int index = hash(key) & (n-1);

Hash函数的注意事项
当键要存储自己编写的类的时候,要保证hashCode和equals方法保持不变性。
hashCode方法保持不变性这样能够导致让原来保存的数据,还能够查询到。
equals方法保持不变性是为了形成链表的时候不出现bug。
装载因子(loadFactor)
为什么要有装载因子呢?
因为HashMap是由数组为基础,然后数组之后又会链接链表或者红黑树的形式来存储数据。但是随着数据的增加,可能会造成链表或者红黑树这种存储形式的影响从而造成查询和新增效率的减慢,所以要进行扩容。
是否进行扩容其实是根据元素的个数和threshold(n*loadFactory)来决定的。
主要由table数组的大小(n)和装载因子(loadFactor)决定。当HashMap容器中的元素个数超过n * loadFactor。
在HashMap中,装载因子laodFactor的默认值为0.75,table数组的默认初始大小为16。也就说,当添加元素个数超过12(16*0.75)个时,HashMap容器就会触发第一次扩容
动态扩容
当HashMap中的元素数量大于threshod的时候,那么就需要进行堆table[]数组进行扩容,并且把容量扩容为原来的2倍,这个时候就需要把原来数组中的元素挨个搬到新的数组当中去。
如何把老的数据挨个转移到新的数组中呢?
因为hash值是不会变的,并且每个节点中是保存了hash的值的。所以理论上只需要根据新的数组进行求模即可
hash & (newCapital-1)。但是实际上JDK8中还是做了优化:
如果node.hash & oldCap == 0,则节点在新table数组中的下标不变;如果node.hash & oldCap != 0
链表树化
为什么要进行树化?
因为链表长度过长的话,会造成查询的损失。所以要进行树化。
树化发生的条件
当链表中的节点个数大于等于8,并且table数组的大小大于等于64时。
树化的优缺点
树化可以提高程序的查询效率,O(n) -> O(logn);但是树化也会增加存储的空间,因为节点需要存储左右两个节点数据,与此同时树化的过程也是有性能消耗的。
反树化
当HashMap删除某个元素的时候,这个时候就可能会发生
反树化,也就是树退化成链表。
1
2
3
4
5
6
7
// 反树化的代码
if (root == null || (movable && (root.right == null
|| (rl = root.left) == null
|| rl.left == null))) {
tab[index] = first.untreeify(map); // too small
return;
}
LinkedHashMap
LinkedHashMap技能实现快速的增删改查操作,又能让容器内元素有序遍历。LRU这个功能可以借助LinkedHashMap来快速的实现。
LinkedHashMap是由哈希表+双向有序链表来实现的。
1
2
3
4
5
6
7
8
9
10
11
12
13
public class LinkedHashMap<K,V> extends HashMap<K,V>
implements Map<K,V> {
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
transient LinkedHashMap.Entry<K,V> head;
transient LinkedHashMap.Entry<K,V> tail;
final boolean accessOrder; //在双向链表中的排序方式
}
排序
accessOrder=false的时候(默认),LinkedHashMap是根据插入的顺序来进行排序的。accessOrder=true则是根据使用的先后顺序来进行排序的。每次最新使用的都会把元素放到末尾。
1
2
3
4
5
6
Map<Integer, String> lmap = new LinkedHashMap<>(16, 0.75f, true);
lmap.put(2, "a"); // 2
lmap.put(5, "b"); // 2->5
lmap.put(18, "c"); // 2->5->18
lmap.put(5, "d"); // 2->18->5
lmap.get(2); // 18->5->2