Overview
In this tutorial, we’ll build a ChatBot using the Spring AI framework and RAG technique. With the help of Spring AI, we’ll integrate with the Redis Vector database to store and retrieve data to enhance the prompt for LLM. Once the LLM receives the prompt with the relevent data, it effectively generate a response with the lastest data in natural language to the user query.
What’s the Rag?
LLM are Machine Learning models pre-trained on extensive data sets from the internet. To make an LLM function within a private enterprise, we must fine-tune it with the organiation-specific knowledge base.
However, fine-tuning is usually a time-consuming process that requires substantial computing resource. Moreever, these is a large probability of fine-tuned LLM generating irrelevant or misleading responses to queries.
This behavior is often refferred to as LLM hallucinations.
In such scenarios, RAG is an excellent technique to restrict or contextualize the response of the LLM. A vector DB plays an important role in the RAG architecture to provide contextual information to the LLM.
But, before an application can use it in RAG architecture, an ETL(Extract Transform and Load) process must populate it:

The Reader retrieves the organization’s knowledge base documents from different sources. Then, the Transformer split the retrieeved documents into smaller chunks and uses an embedding model to vectorize the contents. Finallym the writer loads the vectors or embeddings into the vector DB. Vector DBs are specialized databases that can store these embeddings in a multi-dimenisonal space.
In RAG, LLMs can respond to almost real-time data if the vector DB is updated periodcally from the organization’s knowledge base.
Once the vector DB is ready with the data, the application can use it to retrieve the contextual data from user queries:
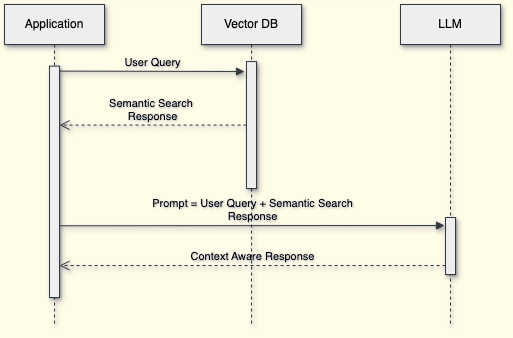
The application forms the prompt combining the user query with the contextual data from the vector DB and finally sends it to the LLM. The LLM generates the response in natural language within the boundary of the contextual data and sends it back to the application.
Implement RAG With Spring AI and Redis
The Redis stack offers vector search services, we’ll use the Spring AI framework to integrate with it and build a RAG-based ChatBot application. Additionally, we’ll use the GPT-3.5 Turbo LLM model from OpenAI to generate the final response.
Prerequisites
For integration with the Redis Vector DB and the OpenAI service, we’ll update the Maven dependencies with the Spring AI libraries.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
<version>1.0.0-M1</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-transformers-spring-boot-starter</artifactId>
<version>1.0.0-M1</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-redis-spring-boot-starter</artifactId>
<version>1.0.0-M1</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
<version>1.0.0-M1</version>
</dependency>
Key Classes for Loading Data Into Redis
In a Spring Boot Application, we’ll create componets for loading and retrieving data from the Redis Vector DB. For example, we’ll load an employee handbook PDF document into the Redis DB.
Now, let’s take a look at the classes involved:
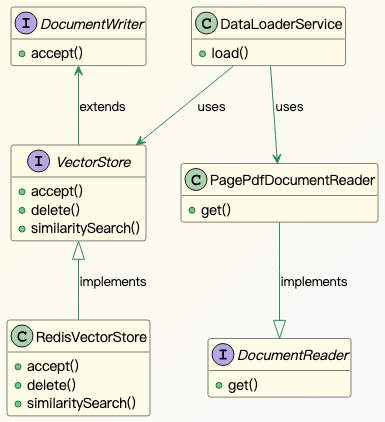
DocumentReader is a Spring AI interface for reading document. We’ll use the out-of-box PagePdfDocumentReader implementation of DocumentReader. Similarly, DocumentWriter and VectorStore are interfaces for writing data into storagte systems. RedisVectorStore, which we’ll use for loading and searching data in Redis Vector DB. We’ll write the DataLoaderService using the Spring AI framewrok classes discussed so far.
Conclusion
In this article, we discussed implementing an application based on the RAG architecture using the Spring AI framework. Forming the prompt with the contextual information is essential to generate the right response from the LLM.
Hence, Redis Vector DB is an excellent solution for storing and performing similarity searches on the document vectors. Also, chunking the document is equally important to fetch the right records and restrict the cost of the prompt tokens.